

Gemini Colonizes Your Google Docs!. .
Free AFIRE Guide | AI Academy | Advertise | AI Mastery A-Z

Plus: Advanced AI was Confusing Until You Learned These 10 Concepts, I Promise!
Everyone is buzzing about Anthropic losing $5000 on every “Claude Code” user, but the real math tells a much different story. The viral claims are wrong guys!
What’s on FIRE 🔥
IN PARTNERSHIP WITH TEST DOUBLE

Test Double software consultants pair AI analysis with pattern-matching across hundreds of clients to accelerate modernization, Rails upgrades, and complexity cleanup.
-
Speed up product discovery, prototyping, and validation
-
Ship AI features without technical risk
Test Double models proven AI practices that increase velocity without introducing technical risk. So your team can integrate AI into existing workflows and ship faster while maintaining quality standards.
Request a 1:1 virtual office hour session to talk about AI tools and workflows. Test Double’s experienced software devs and product managers will share tips and tricks, and point you towards additional resources and ideas.
AI INSIGHTS
❌ $5,000 Claude Code Myth is Wrong!? Real Cost Is Closer to $500
You may have seen the viral claim floating around tech Twitter and LinkedIn: “Anthropic’s $200/mo Claude Code Max plan burns $5,000 in compute per user.”
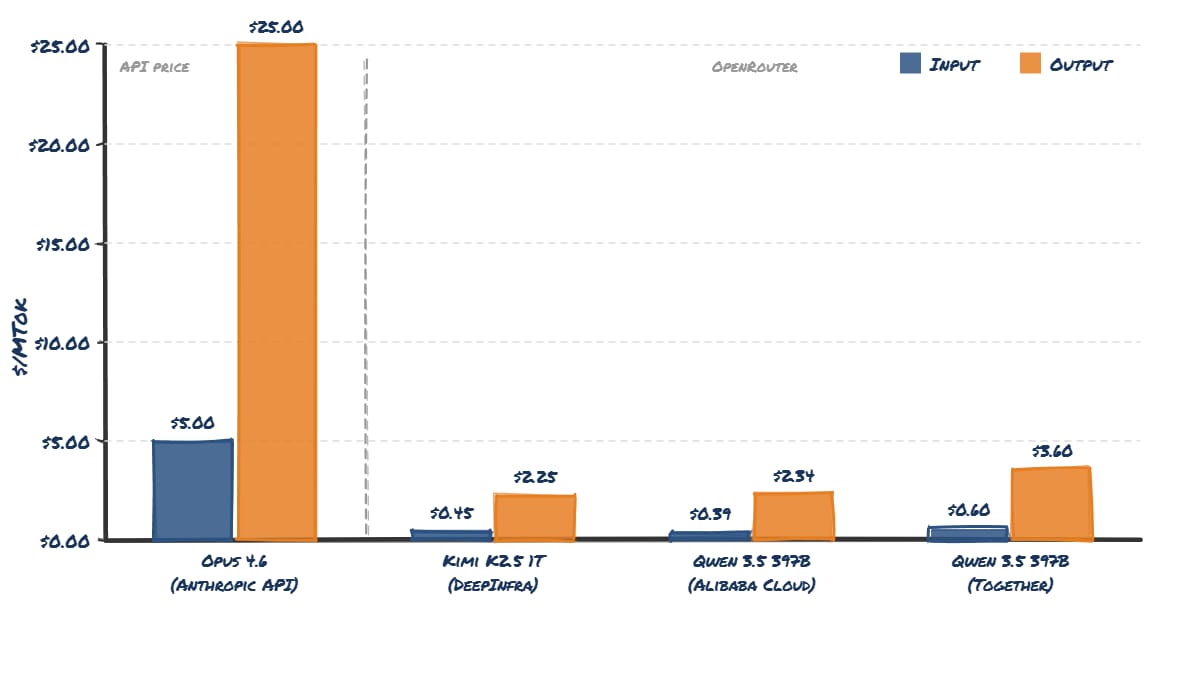
The claim traces back to a Forbes article about Cursor, which said Anthropic’s $200 plan could consume around $5,000 worth of compute. Anthropic’s current API pricing for Claude Opus 4.6 is:
-
$5 per million input tokens
-
$25 per million output tokens
If a power user sends enough prompts, the API-equivalent usage could easily add up to about $5,000 per month. BUT: API pricing is not the same thing as compute cost.
A better way to estimate real inference costs is to look at OpenRouter, both Qwen 3.5 397B and Kimi K2.5 are roughly 10× cheaper than Anthropic’s API pricing.
If a heavy Claude Code Max user generates $5,000 worth of tokens at API pricing, and real compute costs are roughly 10% of that, the true cost looks more like:
≈ $500/month per extreme power user. And those users are rare, fewer than 5% of subscribers would ever hit those limits. Against subscriptions priced between $20 and $200 per month, the math actually works out break-even or profitable.
PRESENTED BY HUBSPOT
Want to get the most out of ChatGPT?

ChatGPT is a superpower if you know how to use it correctly.
Discover how HubSpot’s guide to AI can elevate both your productivity and creativity to get more things done.
Learn to automate tasks, enhance decision-making, and foster innovation with the power of AI.
AI SOURCES FROM AI FIRE
1. Advanced AI was Confusing Until You Learned These 10 Concepts, I Promise! Ditch the basics and master the core mechanics. It provides the exact logic needed to build elite systems today.
2. Google Pomelli AI Just Created the Wildest Photoshoot Yet (For Free)!? Pomelli photoshoot results look unreal. The details are insane and people can’t stop talking about it. Take a closer look.
3. How I Copied a $1K/Day YouTube Channel With AI. Here’s the Automated System! Learn how to script, voice, caption, and publish English-learning podcast videos using a workflow that a solo creator can actually manage.
📽️ Recording is LIVE Soon: Beyond the Template Masterclass
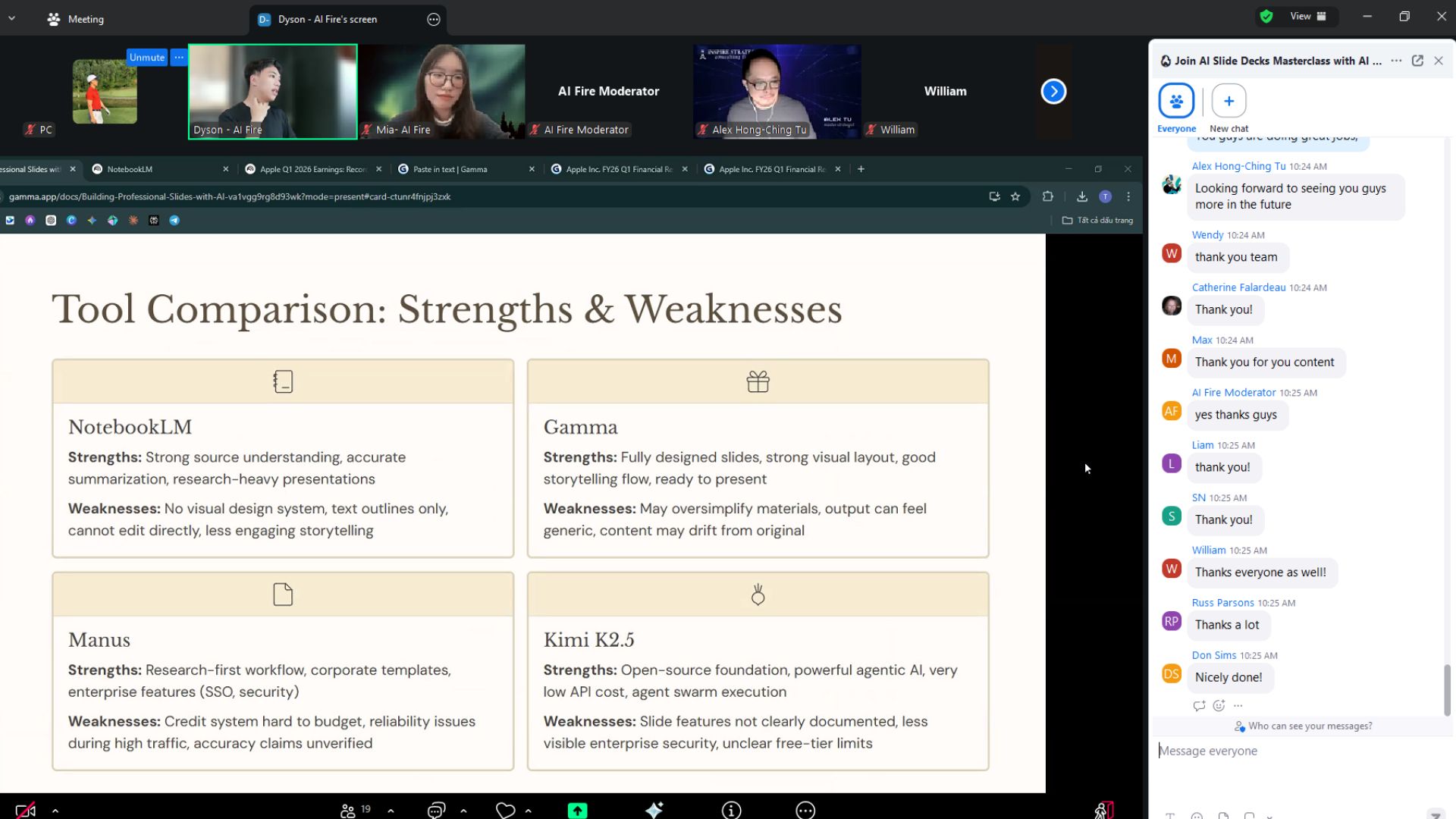
Here’s an image from our Live Workshop
In our latest workshop, we compared 4 powerhouses: Gamma AI, Kimi K2.5, Manus AI, and NotebookLM, and showed exactly how to bypass dated templates to build something that actually wins clients and investors.
If you missed the session, you can now watch the full breakdown of how we go from a raw idea to a polished deck with 100% source fidelity.
⚠️ IMPORTANT NOTE ON THIS RECORDING:
During the live session we had a technical issue with Zoom, and the recording unfortunately broke. So we took some extra time to re-record the entire workshop content so nobody would miss the material.
The only thing missing is the live atmosphere. During the workshop the chat was extremely active with questions, ideas, and discussion. Now you won’t see that conversation, and honestly it feels a little empty without you all there.
So if you’re watching the replay, please keep the discussion going. The community is what makes these workshops fun and useful.
👏 Special shout-out to Alex: Alex was the most active member in today’s workshop. He didn’t just ask great questions instantly. He also helped answer questions from other participants in the chat. Alex, if you’re reading this, we really appreciate your energy!
Here’re all the prompts, notes, tips and final comparison in today’s workshop:
TODAY IN AI
AI HIGHLIGHTS
🎬 OpenAI reportedly plans to integrate Sora’s AI video tools into ChatGPT. If true, millions of users may soon create videos directly from the main chatbot interface.
🥇 Gemini is now inside Google Workspace apps. Docs writes like you, Sheets builds tables with live web data, Slides creates full decks. Watch these features in action.
⚖️ A U.S. court ordered Perplexity to stop letting its AI shop on Amazon, and destroy the data it collected. Its Comet browser accessed without permission. Amazon won!
🚀 Google launched Gemini Embedding 2, a multimodal model that understands text, images, video, and audio together. It’s now available in public preview. See it here.
⚙️ Meta unveiled 4 in-house AI chips, right after spending billions on Nvidia GPUs. It’ll roll out every 6 months, unusually fast for chips. Why build its own silicon now?
💰 Big AI Fundraising: AI legal startup Legora raised $550M, reaching a $5.55B valuation. Used by 800 law firms, the Claude-powered platform is expanding fast in the U.S. amid a booming AI legal tech market.
🛡️ Build Apps, Dashboards, and Reports – All Done with Specialized AI Agents!

Most AI tools still need you to do the work. Spine Swarm doesn’t.
You give it a task – a landing page, prototype, dashboard, or competitive analysis – it deploys a team of specialized AI agents that complete everything automatically. Each agent handles a role:
✅ One searches the live web in real time
✅ One pulls from your own notes and context
✅ One synthesizes everything into a final deliverable
No juggling tools. No endless prompting. Set the task → walk away → come back to a finished project.
NEW EMPOWERED AI TOOLS
-
🚀 InsForge gives agents everything they need to ship fullstack apps. Say the word, and you can deploy to InsForge Cloud or your own domain.
-
🎬 Cardboard is an agentic video editor that gets you from raw footage to final cut fast. It understands what’s in your clips & executes your vision.
-
📣 Teract is your AI reputation coach for LinkedIn, X, Reddit & more. It learns your voice, feeds, and tells you exactly where to show up online.
-
🧩 OpenUI makea your AI apps respond with interactive UI components like cards, tables, forms and charts instead of text.
AI BREAKTHROUGH
🔈 Hume Open-Sourced a Speech Model That Talks 5× Faster Without Hallucinating
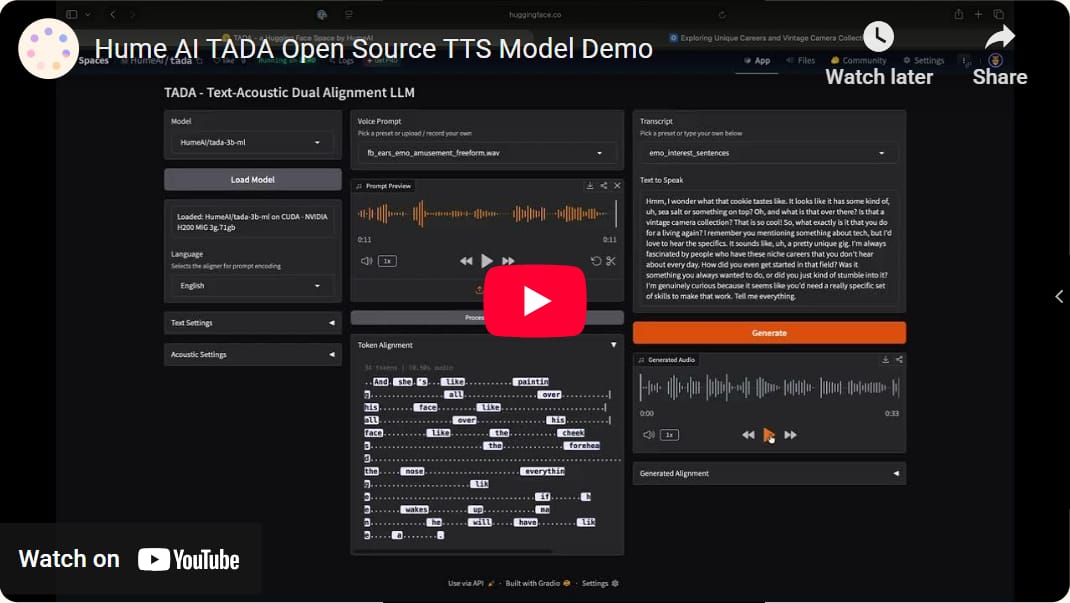
Live Demo
AI speech has a weird problem. Sometimes it skips words or it just speaks too slowly to be practical. Because most text-to-speech systems bolt 2 different models together: one that writes the text & another that generates the audio.
Hume AI thinks that design is the problem. So they released TADA – a speech model that generates text and audio at the same time in a single stream:
-
It generates text tokens & acoustic features together in one unified stream.
-
Across more than 1,000 samples, the model produced zero content errors.
-
It runs at a real-time factor of 0.09, roughly 5× faster than comparable speech models.
-
2,048 tokens represent about 700 seconds of speech, while typical systems top out around 70 seconds.
-
It outputs a perfect transcript alongside the speech with no extra latency.
Hume released the full system publicly. Both are available on Hugging Face and GitHub, along with a public demo where you can test the model.
If the benchmarks hold up in real production systems, this architecture could make real-time conversational AI much easier to deploy, especially for long-form voice agents or streaming applications.
We read your emails, comments, and poll replies daily
Hit reply and say Hello – we’d love to hear from you!
Like what you’re reading? Forward it to friends, and they can sign up here.
Cheers,
The AI Fire Team
Leave a Reply